《用Python写网络爬虫》读书笔记
1.书籍信息
书名:Web Scraping with Python
译名:用Python写网络爬虫
作者:Richard Lawson
译者:李斌
出版社:人民邮电出版社
ISBN:978-7-115-43179-0
页数:157
2.纸张、印刷与排版
16开本,纸张较厚,行、段间距较大,字体较大。
3.勘误
本书勘误文章:http://www.pythoner.com/492.html
出版社勘误页:http://www.epubit.com.cn/book/details/4610
4.笔记与评价
阅读级别:翻译。
推荐级别:细读,适合初学者。
本书面向Python爬虫的初学者,从最基础的抓取方式起步,根据实际需求中可能碰到的问题逐步扩展,此外还介绍了一些Python爬虫常用的三方库和框架。书中没有特别高深的知识,也不会在某一方面过分深入,如果想要了解更深入的知识,可以阅读书中给出的一些参考文档用于补充。
本书中的源代码均可在作者提供的git上进行下载。读者可以很轻松地搭建出与作者相似的环境来进行实践,当然作者也提供了一个demo网站用于为读者服务,不过如果想要学习更加清晰,还是建议大家自行搭建这个demo网站,并自行尝试编码。
实践部分的几个网站,可能不太符合国情,所以大家可以使用一些国内常用于爬取的站点(比如豆瓣、知乎等)来进行实践,这样更能加深自己的理解。
本书共分为9章。
第1章介绍背景,并编写最简单的爬虫。
第2章介绍了正则表达式、BeautifulSoup、lxml三种抓取页面的方式,并对其性能进行对比。
第3章中介绍了磁盘和数据库(MongoDB)两种数据库缓存方式。
第4章引入了并发爬虫执行的概念。当然,这里需要注意的是,爬虫的速率应该进行一定的限制,避免被所爬取网站的防爬策略ban掉。
第5章处理动态表单。AJAX提交表单的方式目前也十分常见,因此传统的方式经常会无法获取到渲染后的源代码,需要使用本章中介绍的逆向工程或是渲染引擎来解析网页。另外,本章还介绍了著名的Selenium框架。
第6章实现自动化表单交互。
第7章处理验证码,介绍了OCR和打码平台两种方式。
第8章介绍了著名的Scrapy框架。
第9章在几个真实网站上进行了实践。
巧合的是,有一本英文同名的著作也在前几个月出版了中文版本(《Python网络数据采集》),过段时间把那本书看完之后,我也会写一下那本书的读书笔记,并谈一下两本书的区别。
5.思维导图
思维导图(图片版)
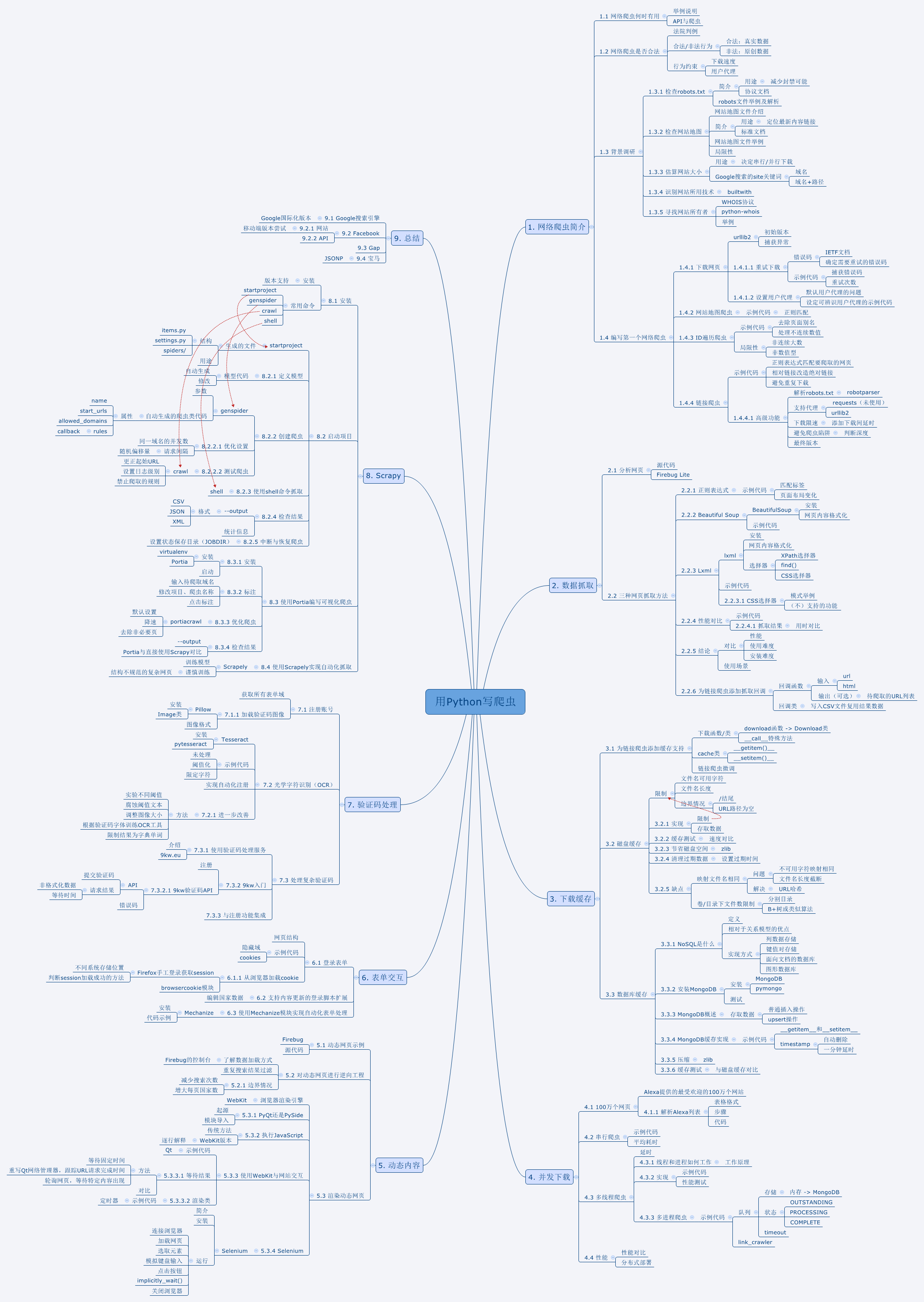
《用Python写网络爬虫》思维导图
思维导图(xmind):《用Python写网络爬虫》思维导图(xmind)
本文内容遵从CC3.0版权协议,转载请注明:转自Pythoner
本文链接地址:《用Python写网络爬虫》读书笔记

学习了,值得看看的
这个挺不错的
你好,我在学习《用Python写网络爬虫》,在自行搭建这个demo网站的时候碰到了问题,我用的环境是Ubuntu:14.04,用命令curl http://127.0.0.1:8000/places -uadmin -padmin能显示网页的内容,但是用curl http://10.10.10.17:8000/places -uadmin -padmin总是报错curl: (7) Failed to connect to 10.10.10.17 port 8000: Connection refused。我应该修改哪个文件中的IP啊??谢谢
确认下这个是不是你本地的IP,防火墙是否允许
D:\scrapybook>vagrant up –no-parallel
Bringing machine ‘web’ up with ‘docker’ provider…
Bringing machine ‘spark’ up with ‘docker’ provider…
Bringing machine ‘es’ up with ‘docker’ provider…
Bringing machine ‘redis’ up with ‘docker’ provider…
Bringing machine ‘mysql’ up with ‘docker’ provider…
Bringing machine ‘scrapyd1’ up with ‘docker’ provider…
Bringing machine ‘scrapyd2’ up with ‘docker’ provider…
Bringing machine ‘scrapyd3’ up with ‘docker’ provider…
Bringing machine ‘dev’ up with ‘docker’ provider…
==> web: Docker host is required. One will be created if necessary…
web: Vagrant will now create or start a local VM to act as the Docker
web: host. You’ll see the output of the
vagrant upfor this VM below.web:
docker-provider: Box ‘lookfwd/scrapybook’ could not be found. Attempting to
find and install…
docker-provider: Box Provider: virtualbox
docker-provider: Box Version: >= 0
The box ‘lookfwd/scrapybook’ could not be found or
could not be accessed in the remote catalog. If this is a private
box on HashiCorp’s Atlas, please verify you’re logged in via
vagrant login. Also, please double-check the name. The expandedURL and error message are shown below:
URL: [“https://atlas.hashicorp.com/lookfwd/scrapybook”]
Error:
D:\scrapybook>
值得学习,收藏了 ,去买来看看
博主忙啥去了?失踪了吗.
怎么不继续写了?