[Python代码]人人网状态墙抓取脚本
在很多活动中,会使用诸如人人墙、微博墙这类产品增强现场的氛围,而在活动后,如何保留这些状态呢?我们不可能会指望着以后再登录这些网站一页一页翻看下去,因为像人人墙15条状态一页,一次活动很容易就几十上百页,甚至不能指望这些网站永久的正确保留这些状态墙(比如,现在去查看比较早的人人墙,发表时间一律是2011-09-06 01:26,原始的时间数据就已经丢失了)。这时,我们就需要把这些状态墙抓取下来留作永久保存的几年了。
在昨天的文章里曾经提到过,写那个程序的本来目的是为了抓取去年我参加的一次活动时候人人网状态墙上面的状态。由于目前的人人墙状态查看不再需要登录,因此,对原来的代码进行了一定的修改。
这个程序包括3个文件,config.py、renren.py、wall.py。其中renren.py和config.py参见昨天的文章(点此进入)。
config.py增加一句,作为人人墙的基础地址:
|
1 |
WALLURL = r'http://w.renren.com/wall/' |
对人人墙的源代码进行分析,发现每页的15条状态并没有出现在源代码中。使用firebug查看,发现这些状态在一个名为id='info-discuss'的div中。再通过查看post的信息,发现实际上这些状态的来源网址是“http://w.renren.com/wall/[wall_id]/wallDoing/[page]”,如下图中的蓝色框所示:
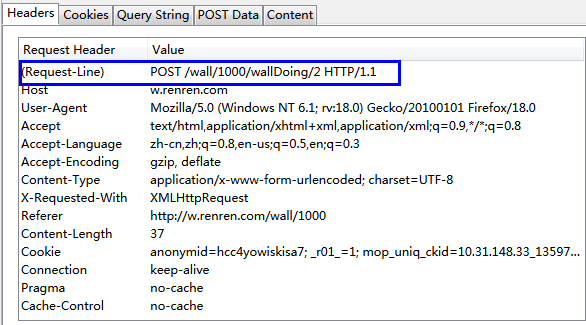
进一步查看这个地址里的内容,如下图所示:
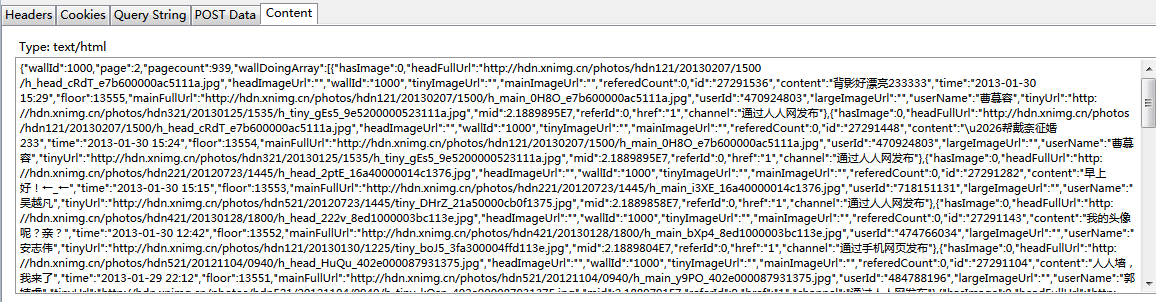
可以看到,这是一个json格式的文件,其中wallId是人人墙的ID,page是当前页,pagecount是总页数,wallDoingArray是状态列表。在状态列表中,包括有用户ID、用户姓名、头像地址、状态内容、状态楼层、时间等信息,在下面的代码中我们只用用户ID、姓名、状态内容和时间几项。
下面是wall.py的内容:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
# -*- coding: utf-8 -*- import json import re import os import config import renren class Wall(renren.Renren): def __init__(self, wall_id): super(Wall, self).__init__() self.wall_id = wall_id self.url = config.WALLURL + wall_id self.title = self.people = self.status = '' self.all_status = [] self.title_re = re.compile(r'<h2 class="a-sname" title="(?u)(\w+)">') self.people_re = re.compile(ur'<span class="a-statu">(\d+)人参加') self.status_re = re.compile(ur'(\d+)条状态</span>') self.sms_re = re.compile(r'sms_(\d+)') def get_wall(self): self.operate = self._get_response(self.url) mainpage = self.operate.read().decode('utf-8') self.title = self.title_re.search(mainpage).group(1) self.people = self.people_re.search(mainpage).group(1) self.status = self.status_re.search(mainpage).group(1) # Get pagecount raw_wall = self._get_response(self.url + '/wallDoing/1').read() json_wall = json.loads(raw_wall) pagecount = json_wall['pagecount'] # Get status for page in range(1, pagecount + 1): print 'Reading Page %d of %d ...' % (page, pagecount) raw_wall = self._get_response(self.url + '/wallDoing/' + str(page)).read() json_wall = json.loads(raw_wall) try: for each in json_wall['wallDoingArray']: status_info = { 'time': each['time'], 'userName': each['userName'], 'userId': each['userId'], 'content': each['content'], } self.all_status.append(status_info) except: None self._write_file('wall_' + self.wall_id + '.html', self.__format_output()) def __format_output(self): output = [ '<!DOCTYPE HTML>', '<html lang=zh-cn>', '<head>', '<meta charset=utf-8>', '<title>' + self.title + '</title>', '</head>', '<body>', '<h1>' + self.title + '(<a href=' + self.url + '>原始地址</a>)</h1>', '<h2>' + self.people + '人参加 | ' + self.status + '条状态</h2>', ] for each_status in self.all_status: # 判断手机用户 sms_number = self.sms_re.search(each_status['userId']) if not sms_number: formated_status = '<p><a href="http://www.renren.com/' + each_status['userId'] + '/profile">' formated_status += each_status['userName'] + '</a> ' else: formated_status = '<p>' + each_status['userName'] + ' ' formated_status += each_status['time'] + '<br />' formated_status += each_status['content'] + '</p><hr />' output.append(formated_status) output += ['</body>', '</html>',] return [line + os.linesep for line in output] if __name__ == '__main__': wall_getter = Wall('人人墙ID,如1000') wall_getter.get_wall() |
在这里,首先取得总页数,执行一个循环,读取每页中的状态信息(这里需要使用到json模块),将所有状态总结到一个列表中,再将这些状态进行格式化,输出到文件中。
在格式化输出中,可以看到有一处是判断用户是否为手机用户的,如果是手机用户,在json文件的userId中显示的是sms_[手机号]这样一个格式,而userName则是一个中间四位置为*的手机号,在这里我选择不完全公开手机号。
本文内容遵从CC3.0版权协议,转载请注明:转自Pythoner
本文链接地址:[Python代码]人人网状态墙抓取脚本

暂无评论